Our team of experts is ready to assist you with your integration.
The Rise of Open Data Lake Formats
As data volumes continue to grow, open data lake formats have become a popular choice for large-scale data storage and analytics. These formats offer several advantages:
Storing data in cloud object storage significantly reduces costs.
Native support for columnar formats like Parquet enhances performance for analytical queries.
Open standards and formats enable seamless data integration and sharing across an organization, making them ideal for maintaining a single source of truth.
Among the most prominent open data lake formats are Apache Iceberg, Apache Hudi, and Delta Lake. Apache Iceberg has gained significant traction and is supported by major data warehouses and cloud providers. AWS's recent introduction of native S3 table support for Iceberg further solidifies its role in modern data ecosystems.
While open data lake formats offer numerous benefits, they aren't a one-size-fits-all solution. Columnar storage formats are optimized for OLAP (Online Analytical Processing) workloads, but have limitations when it comes to:
These require row-based storage for efficient updates and writes. To support high transaction rates, the storage layer must be positioned higher in the memory hierarchy, as object storage has high I/O latency.
These involve retrieving specific records quickly, often for exploratory analysis or interactive queries that demand low-latency responses.
In this blog, we will dive deep into traditional search workloads on open data lake formats like Apache Iceberg, exploring why Iceberg struggles with search at scale and how integrating it with Mach5 can bridge the gap for real-time, high-performance search.
Search workloads are intended to quickly retrieve specific records from massive datasets with minimal latency. Unlike traditional analytical (OLAP) workloads—which focus on aggregating data and executing long-running batch processes—search workloads emphasize real-time, interactive querying.
Key Characteristics of Search Workloads:
Users explore vast datasets, often without predefined query patterns.
Queries often involve multiple filters and full-text predicates.
Users demand sub-second response times to support interactive analysis.
Search systems must accommodate queries (e.g. wildcard matching and synonym recognition)
Differences from Analytical Workloads:
Understanding these distinctions clarifies why open data lake formats—while excellent for analytical processing—often struggle with the speed and efficiency required for search workloads. This gap necessitates specialized solutions, like Mach5, that leverage advanced indexing and caching mechanisms to deliver real-time, low-latency search capabilities.
Although Apache Iceberg excels at large-scale analytical workloads, it presents challenges for search-intensive use cases due to its reliance on full table scans. To optimize search performance, efficient partitioning, indexing, and caching strategies are required. However, Iceberg's support for these features is limited:
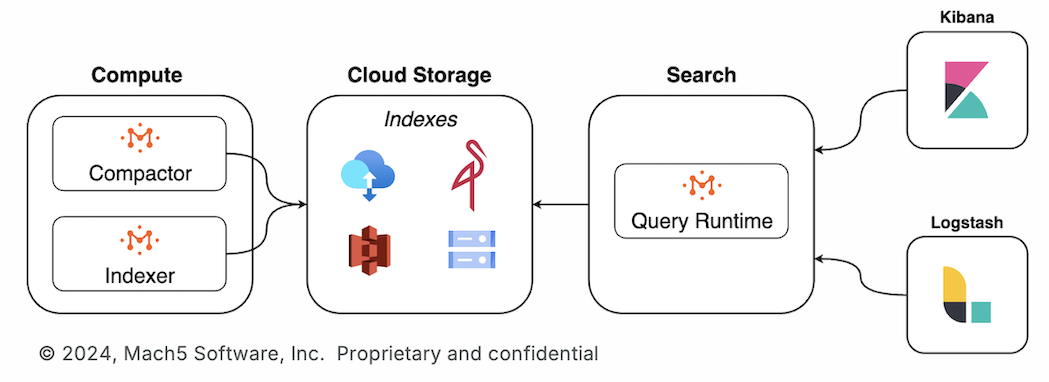
Apache Iceberg is a powerful format for managing large-scale data lakes, but it wasn't designed for real-time, low-latency search. This is where Mach5 excels, offering a specialized search-optimized layer that complements Iceberg's strengths. By integrating Mach5 with Iceberg, organizations can unlock high-performance search capabilities while maintaining cost-efficient storage and governance.
Why Mach5?
Avoiding full table scans by leveraging advanced indexing and caching.
Mach5's indexing supporting complex filters and predicates, including fuzzy matching and full-text queries.
Mach5 maintains synchronized, search-optimized indexes of Iceberg data ensuring real-time updates without duplicating storage costs.
How Mach5 Enhances Search Performance
Apache Iceberg tracks changes over time, making it simple to identify which data files do not have an up-to-date index. Mach5 utilizes this capability to efficiently index newly arrived records--including appends, deletes, and updates--ensuring that search queries reflect the most recent data state. Here's how the process works:
By integrating Apache Iceberg with Mach5, organizations can create a hybrid architecture that leverages the cost-effective, scalable storage of Iceberg alongside Mach5's real-time, low-latency search capabilities. This integrated solution offers several key advantages:
This hybrid approach unlocks new possibilities by marrying scalable data lake storage with high-performance search, enabling organizations to optimize their data operations and meet diverse workload requirements seamlessly.
Ready to supercharge your data search? Learn more about how Mach5 can optimize your Iceberg-based infrastructure today.