Blog
Key Issues in Building a Low-Latency Search Engine on Object Storage

TABLE OF CONTENT
Need Help ?
Our team of experts is ready to assist you with your integration.
Key Issues in Building a Low-Latency Search Engine on Object Storage
Over the last decade, object storage systems—like Amazon S3, Azure Blob Storage, and Google Cloud Storage—have become indispensable for handling ever-growing volumes of data. More recently, the growth of AI workloads has also made object stores invaluable, leading NV to release the AIStore project. Inexpensive, highly durable, and practically limitless, they store everything from logs and media to entire data lakes. But despite their obvious benefits, object stores present a formidable challenge when it comes to low-latency search over large datasets
Traditional search engines (e.g., Elasticsearch, Apache Solr, or OpenSearch) excel when running on low-latency SSDs or specialized storage layers that allow fine-grained, random access. In contrast, object stores exhibit higher latency, rely on HTTP or similar protocols for data retrieval, and typically do not permit random block-level reads. This environment undermines the assumptions that many search engines were built upon—making it incredibly difficult to deliver sub-second or real-time query responses
However, if one were able to combine the virtues of object storage with low-latency search responses, the benefits can be game changing.
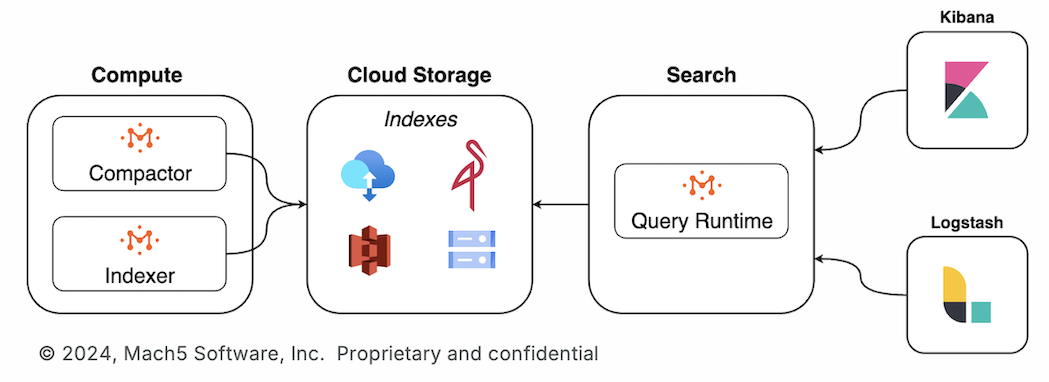
This article breaks down why creating a low-latency search engine on top of object storage is so challenging. We will examine the technical barriers, architectural constraints, and operational considerations that make this task more complex than simply “scaling up” a standard search engine. Along the way we will learn how Mach5’s Search Engine- Mach5 Search overcomes these challenges to create a cost-effective, adaptive, and converged platform for integrated search and analytics on object storage.
1. Pros and Cons of Object Storage
1.1 The Upside: Infinite, Cheap, and Durable
Object stores have become the de facto solution for businesses and individuals seeking to park large volumes of data. They offer:
•
Seemingly Infinite Capacity:
Scales up automatically without complex volume management.
•
High Durability:
Top-tier services promise eleven 9’s (99.999999999%) durability or similar guarantees.
•
Cost-Effectiveness:
Pay-as-you-go models can be cheaper than maintaining on-premises SANs or NAS solutions.
1.2 The Downside: High Latency and Limited Access Patterns
Despite these benefits, object storage does not behave like a local file system or block storage. It typically:
•
Has Higher Latency:
Each read or write might involve a round-trip through HTTP-based APIs, making random small reads expensive.
•
Does Not Allow Block-Level Access:
Data must be fetched in whole or in large chunks, forcing retrieval patterns that are inefficient for fine-grained lookups common in search engines.
•
Follows a Flat Namespace:
Although files can appear to be in folders, these are effectively just key prefixes. A standard hierarchical directory structure with local caching and typical POSIX semantics does not exist
2. Why Low Latency Matters in Search
Modern user expectations demand quick, interactive responses. Whether powering a product catalog, log analysis tool, or enterprise knowledge base, search queries must execute in real-time or near-real-time. Delays beyond a few seconds degrade user experience and hinder time-sensitive analytics.
•
Real-Time Analytics:
DevOps teams use search to spot errors in logs, identify anomalies, and respond to incidents quickly
•
Interactive Applications:
Online shops or media services need fast search to keep users engaged.
•
Compliance & E-Discovery:
Legal and audit teams rely on rapid full-text search for investigations under strict time constraints.
However, delivering sub-second latencies for queries over data in object storage is hard.
3. The Hard Parts of Building a Low-Latency Search on Object Storage
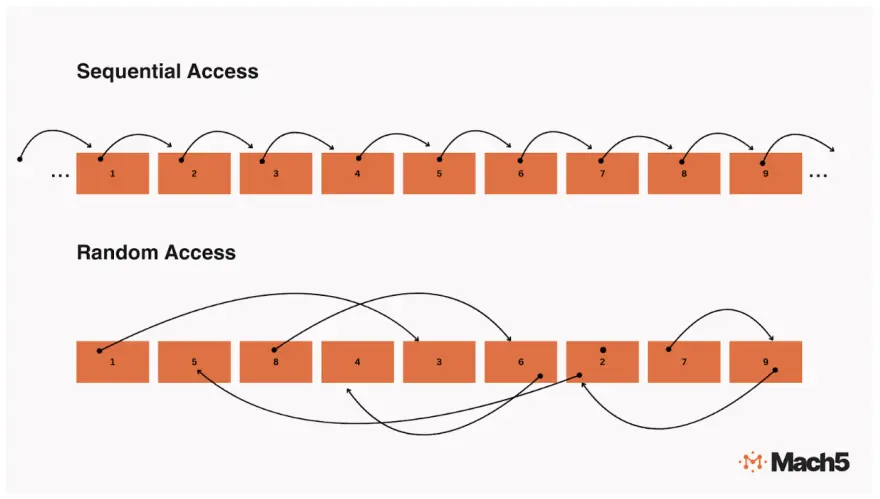
3.1 Random Access vs. Bulk Reads
A hallmark of most full-text search engines is random I/O. They read small segments of data (posting lists, skip lists, term dictionaries) scattered across index files. On a local SSD, random reads are relatively cheap; on an object store, each read is a networked operation with significant overhead.
•
High Overhead per Request:
HTTP round-trips can add tens to hundreds of milliseconds each.
•
No Fine-Grained Blocks:
Fetching small segments isn’t straightforward, so systems may need to grab entire chunks or objects, which can be hundreds of MBs or more.
Result :Query performance stalls if you rely on repeated small lookups from object storage. You either need extensive caching or a re-designed index that minimizes random reads.
3.2 Merging and Managing Large Index Segments
Full-text search engines typically merge smaller index segments into bigger ones to reduce query overhead. Merging is I/O-intensive under the best conditions; in an object store environment, it becomes even harder:
•
Multiple Large Downloads:
Each merge step could require bulk downloading entire segments from object storage.
•
Frequent Writes:
After merging, the new, larger segment must be uploaded back.
•
High Latency at Scale:
Doing this repeatedly or for real-time indexing use cases can quickly degrade performance and inflate bandwidth costs.
Result :Real-time ingestion or frequent updates become cumbersome. Traditional merging strategies can lead to extreme slowdowns, especially for workloads that demand constant ingest-and-query patterns.
3.3 Data Freshness and Eventually Consistent Writes
Object stores often provide eventual consistency: newly uploaded objects might not be immediately visible for read or list operations. This can introduce complications for a low-latency search engine:
•
Stale Metadata:
If your indexer is scanning an object store bucket, it might not see the newest uploads in time for real-time indexing.
•
Handling Deletes/Updates:
Deletions or updates to objects may lag behind the search index, leading to out-of-sync results
Result :Achieving real-time or near-real-time indexing is challenging due to the eventual consistency guarantees provided by some object stores. You must incorporate a layer that reliably tracks changes, such as via event notifications, a message queue, or a commit log, which adds complexity.
3.4 Large, Distributed Architecture
A low-latency search engine is typically distributed across multiple nodes to handle data volume and query concurrency. In an object store scenario, this can lead to:
•
Orchestrating Many Components:
Indexers, query nodes, caching layers, and the object store itself all need to coordinate.
•
Cache Invalidation:
If you rely on local caches to offset object store latency, ensuring consistency among nodes is complicated—especially if data changes rapidly.
•
Network Bottlenecks:
Depending on how data is replicated or how queries fan out, you can easily saturate network links or exceed egress quotas.
Result :Operating a fully distributed, low-latency search system becomes a significant engineering challenge. You must carefully tune caching, replication, and data partitioning strategies.
3.5 High Costs of Frequent Data Movement
Object storage is cheaper for resting data, but costs can rise quickly if you’re constantly moving large volumes in and out:
•
Egress Charges:
Most cloud providers charge for data reads (GET requests) and data transferred outside the region.
•
API costs:
Cloud providers charge based on the number of requests made to the object store to read and write data.
•
Compute Overheads:
If you spin up large clusters or specialized instances to maintain local caches, operational costs escalate.
•
Re-Indexing Cycles:
Periodically re-indexing massive datasets can result in substantial data movement and duplication.
Result :Without a carefully designed architecture that minimizes data transfers and merges, you risk ballooning your cloud bills while still not achieving the desired low-latency performance
4. Strategies to Overcome These Challenges
4.1 Rethink Index Formats for High-Latency Environments
Design or adopt index structures that reduce the need for random reads :
•
Chunked Segments:
Group data into larger, sequential chunks that can be fetched in a single or minimal number of requests.
•
Sparse Indexes:
Use skip-level pointers or coarse-grained indices so that queries only touch relevant chunks, avoiding small random lookups.
Mach5 Search implements a multi-level, multi-dimensional index structure specially optimized for retrieving the minimal data from object storage with the lowest latency.
4.2 Cache Aggressively
Object stores often provide eventual consistency: newly uploaded objects might not be immediately visible for read or list operations. This can introduce complications for a low-latency search engine:
•
Local SSD Caches:
Maintain partial or entire index segments locally on SSD-based storage.
•
Hot-Tier Architecture:
Frequently queried data or recent writes live in a faster, direct-attached or networked filesystem, and only cold data resides in the object store.
Mach5 Search strategically uses a combination of SSDs and memory of the compute nodes for caching different parts of the index. In conjunction with the index design described in 4.1, this gives us a big boost in reducing query latency while only using a small amount of cache space compared to the total amount of data in object storage.
4.3 Event-Driven Ingestion
While 4.1 and 4.2 focused on query latency, here we focus on data latency and freshness. Eventual consistency and data freshness must be handled through event notifications:
•
Message Queues or Streaming:
Connect the object store to a pipeline (e.g., Kafka, Kinesis) that reliably tracks new or modified objects, triggering immediate index updates.
•
Checkpointing & Versioning:
Keep track of the last processed object version, rechecking if needed to avoid missing updates.
Mach5 Search implements a timeline consistent notification protocol as part of how it performs transactions against the object store, so all readers know when the data has changed. Furthermore, each query node monitors the current query workload and builds a local AI model to predict future data that will be needed. When data change notifications are received, the node proactively prefetches new data based on its predictive model further reducing latency for future queries.
4.4 Hybrid Real-Time and Batch Approaches
To balance cost and performance:
•
Near-Real-Time Indexing for New Data:
Quickly ingest recent or critical data into a high-performance layer.
•
Scheduled Batch Processes for Historical Data:
Index older or less frequently accessed data periodically, accepting that queries on this older data might be slower or less frequent.
Mach5 Search implements a scheduler that automatically balances data freshness with resource consumption to ingest data in a timely manner while staying under budget.
5. Final Thoughts
Building a low - latency search engine on top of high - latency, eventually consistent object storageis a significant engineering challenge. The friction arises from fundamental mismatches: object stores thrive on large sequential writes and reads, while search engines depend on small, random-access reads. Achieving sub-second query responses means re-architecting for coarse-grained data retrieval, leveraging caching heavily, and carefully managing how and when data moves between storage layers.
The payoff, however, can be enormous. By giving end-users quick access to terabytes or petabytes of unstructured data living in object stores, organizations can unlock insights, accelerate troubleshooting, boost user engagement, and foster data-driven decision-making. Yet, any team taking on this challenge must come prepared: from index format redesign to robust caching strategies, every step requires an understanding of object store limitations and how to best navigate them.
We bring you Mach5 Search with all the virtues of a low-latency search and analytics platform while providing all the benefits of object stores, freeing you up to come up with interesting applications for the platform and not worry about cost and performance optimization.