Blog
Using Multi-Warehouse Architecture to Accelerate Query Performance for Large-Scale Analytics

TABLE OF CONTENTS
Need Help?
Our team of experts is ready to assist you with your integration.
Introduction
For all companies with complex environments and/or heterogeneous workloads, data and its management is the backbone of their operations. Such teams increasingly rely on shared datasets to serve different use cases with different requirements. For example, one team can use the data for creating a real-time monitoring dashboard that demands sub-second latency while a research team runs heavy, historical analytics on the same data.
Another example can be a multi-tenant SaaS platform where thousands of customers query their own isolated data, all while the internal threat intelligence team scans across tenants for emerging patterns.
Legacy architectures like Elasticsearch struggle to scale efficiently under such mixed workloads. Low-latency queries contend with long-running analytics, forcing teams to spin up additional clusters wasting resources and driving up costs.
Mach5’s multi-warehouse architecture solves this by isolating compute into purpose-built warehouses, ensuring every workload gets the right resources at the right time without interference or output lag.
In this blog we explore how this approach delivers predictable performance and operational simplicity in comparison to scaling a cluster.
Challenges of Running Multiple Queries on Single Cluster
Having data that resides on the same nodes where compute runs becomes challenging because:
•
Resource contention
Running multiple workloads on a single warehouse can cause unpredictable latency and uneven throughput.
•
Compute limitations
Scaling a single warehouse for all workloads often wastes resources and increases costs.
•
Operational complexity
Manually managing compute for varying workloads is inefficient and error-prone
Since companies are accustomed to using Elasticsearch and the issues that come with it, teams and business often suffers in the following ways:
•
Unpredictable performance
Short queries slow down due to heavy analytical workloads, and vice versa.
•
Higher costs
Overprovisioning compute to meet peak demand wastes resources.
•
Limited scalability
Concurrent workloads create contention, making throughput non-linear under load.
To eliminate these bottlenecks, there is a need for an architecture that separates compute from storage and isolates workloads without duplicating data. That’s where multi-warehouse architecture comes in.
What is Multi-Warehouse Architecture?
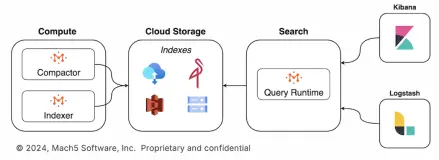
A Multi-warehouse architecture is a design pattern where compute is decoupled from storage and provisioned as isolated, purpose-built warehouses each dedicated to a specific workload type. In Mach5, compute warehouses independently access a shared, immutable index layer stored on object storage (e.g., S3, GCS, MinIO), allowing teams to assign resources based on workload characteristics without duplicating data.
Each Mach5 warehouse can be sized, paused, resumed, or scaled elastically to support varied workloads: low-latency dashboards, ad-hoc threat analysis, batch indexing, or model training all without interference or overlapping dispute.

Here’s how Mach5’s multi-warehouse architecture delivers these capabilities in practice:
1. Smarter compute isolation
- Lightweight warehouses handle sub-second, high-frequency queries.
- Large analytical warehouses manage heavy aggregations and historical data scans.
- Each warehouse has isolated compute, memory, and I/O to prevent interference.
2. Decoupled compute and storage
- Multiple warehouses can query the same indexed datasets independently with no logging and deduplication of data as it sits in object store
- Compute can be scaled up, down, or paused without affecting data availability or query correctness.
3. Optimized for efficiency and cost
- Workloads run concurrently without contention.
- Predictable low latency and throughput, even under bursty or overlapping queries.
- Indexed data and parallelized execution accelerate large aggregations.
4. Operational simplicity
- Teams can right-size warehouses per workload.
- Supports interactive analytics, dashboards, batch transformations, and model training pipelines simultaneously.
- Warehouses can be spun up, paused, or destroyed via a simple API or UI call allowing teams to scale and compute dynamically based on workload needs without operational overhead.
- Start with a small set of hot fields and expand once you validate gains.
Conclusion
As data demands grow more complex, the ability to isolate workloads without duplicating data becomes essential. While traditional systems like Elasticsearch can perform the job, the operational overhead, rigid scaling, and escalating costs make them increasingly inefficient for dynamic, multi-workload environments.
Mach5’s multi-warehouse architecture delivers on this by decoupling compute from storage, ensuring each workload gets the compute resources it needs; without interference, scaling bottlenecks, or redundant clusters. The result is predictable performance, cost-efficient scaling, and operational simplicity that legacy architectures struggle to match. Here's how the two approaches compare:
| Multi - Warehouse Architecture | Legacy Cluster Architecture | |
|---|---|---|
| Workload Isolation | Each warehouse runs independently with dedicated compute, memory, and I / O ensuring predictable performance across diverse workloads. | All workloads share the same resources, leading to contention and unpredictable latency under mixed query loads. |
| Elasticity & Cost Efficiency | Warehouses can scale up, down, or pause individually based on workload demand, optimizing cost per query. | Scaling the entire cluster increases cost even when only part of the workload needs more compute. |
| Operational Flexibility | Enables teams to run concurrent analytics, dashboards, and batch pipelines without interference. | Requires manual workload scheduling and capacity planning to avoid bottlenecks. |