Blog
Enabling Low-Latency Search on the Cloudflare Data Platform
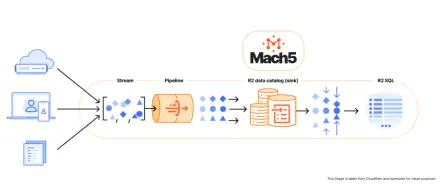
TABLE OF CONTENTS
Need Help?
Our team of experts is ready to assist you with your integration.
Introduction
As technology advances, the modern data stack is evolving toward composable, best-of-breed services built on open standards. The new Cloudflare Data Platform embodies this vision, delivering scalable data ingestion and durable storage with Apache Iceberg on R2. It provides a solid foundation for your data, but a foundation is only the start. While excellent for large-scale analytics, its native query layer isn't designed for the sub-second performance required in operational and security use cases.
For security and observability teams, speed is everything. When an incident fires at 2:13 a.m., “I'll get back to you after this query finishes scanning terabytes of data” is not an option. Analysts need to pivot instantly across IPs, user IDs, error codes, and URLs, slice by tenant or environment, and zero in on the few events that matter. That's a search problem, not a batch analytics problem.
This is where Mach5 changes the game. It doesn't replace your data lake; it upgrades it. Instead of forcing you to copy data into a separate search cluster, Mach5 connects directly to your Iceberg tables in R2. It builds a lightweight, highly optimized search index on top of your existing data, unlocking true low-latency search.
In this post, we'll show how pairing Cloudflare's data backbone with Mach5's specialized search engine lets you keep a single, canonical source of truth in Iceberg, while powering instantaneous dashboards, real-time alerts, and interactive queries that give your teams the speed and confidence they need.
About Cloudflare Data Platform
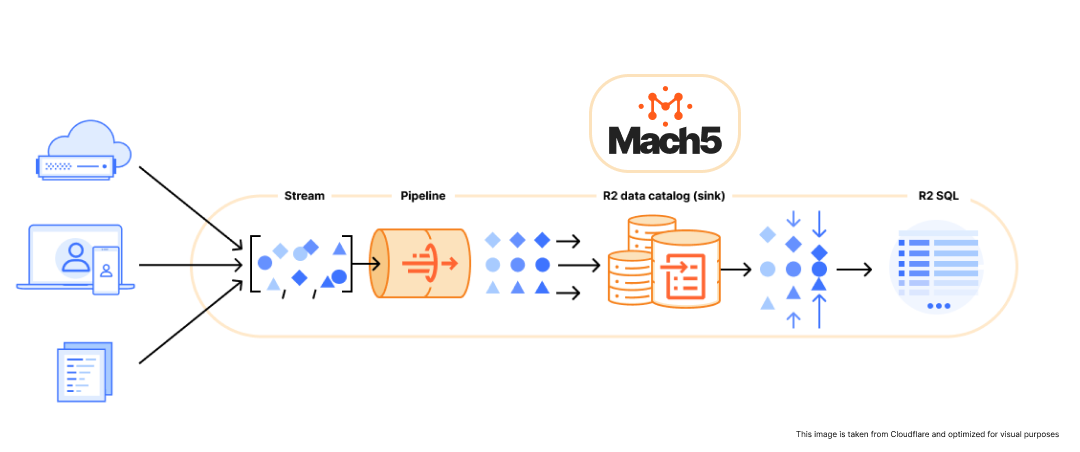
Cloudflare has engineered a data platform that solves many of the hardest problems in data ingestion and storage at scale. It's a cohesive pipeline designed for the modern, cloud-native world, moving data efficiently from source to a reliable, open-format repository.
At its core, the platform's strength lies in its key components:
•
Ingest Store pipeline
Cloudflare Pipelines receive events from your apps and edge properties, apply lightweight SQL-style transforms or redaction, and land them into R2 object storage registered in the Iceberg Catalog.
•
Open tables, durable storage
Iceberg on R2 gives you transactionally consistent, open-standard tables. That means schema evolution without chaos, partitioning you control, and compatibility with the broader data ecosystem.
•
Compaction and file health
Streaming into object stores tends to create lots of small files. Cloudflare's compaction patterns keep table health in check so downstream engines don't pay a penalty on every query.
•
Global infra, usage-based economics
You don’t run clusters here. You rely on Cloudflare’s platform to scale ingest and storage while staying within an open-table model.
This combination makes the Cloudflare Data Platform an exceptional choice for creating a centralized data lake. Services like R2 SQL provide a valuable interface for running large-scale analytical scans and business intelligence reporting. However, this workload pattern is fundamentally different from the demands of low-latency search.
Challenges of Low Latency Search on Iceberg
The architectural choices that make Parquet and Iceberg so effective for analytics are the very same reasons they are ill-suited for high-performance search. Parquet is a columnar format, meaning data for each field (like ip_address or user_id) is stored together. This is incredibly efficient when you need to aggregate a single column across billions of rows, as the query engine can ignore all other column
However, consider the “needle-in-a-haystack” search. To find all records matching a specific user_id, a query engine running on raw Parquet files must perform a brute-force scan. It has to load file after file from object storage, decompress the relevant columns, and scan through every single value to find the few that match.
To put this in perspective, imagine trying to find every mention of a specific character in a library full of books. The analytical approach is like reading every single book from cover to cover which is thorough, but incredibly slow. A search engine, by contrast, is like using the library’s master index; it tells you exactly which books, pages, and paragraphs contain the character's name, allowing you to go directly to the answer.
This technical mismatch creates several performance bottlenecks for search on data lakes:
•
High I/O Amplification
Object storage like R2 is optimized for throughput, not for the rapid, small reads required for search. A single search query can trigger hundreds or thousands of slow GET requests to scan Parquet files, creating massive I/O latency.
•
Wasted CPU Cycles
The query engine spends significant CPU resources decompressing and scanning terabytes of data, only to discard 99.999% of it. This is computationally inefficient and expensive.
•
Absence of Search-Specific Data Structures
The key to fast search, especially for text, is the inverted index. This is a data structure that maps terms (like “error,” “login,” or an IP address) directly to a list of documents containing them. Parquet has no such structure. Without it, every search is a full scan.
For the interactive, sub-500ms response times that users expect from a search bar or a real-time dashboard, you cannot rely on scanning. You need a purpose-built search layer that creates and leverages these optimized indexes. This is exactly where Mach5 Search comes in. Let’s take a look at how Mach5 and Cloudflare work together.
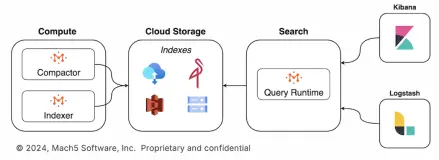
How Cloudflare and Mach5 work Architecturally
The integration between Cloudflare and Mach5 is architecturally elegant because it leverages Iceberg as a clean, standardized interface. There is no complex ETL pipeline to build or brittle integration to maintain. The data flow is logical and efficient.
Think of Cloudflare as the data backbone and Iceberg tables as the contract where all data is formalized and governed. Mach5 treats that contract as the source of truth and layers search capability on top.
What Mach5 does here
•
Search-optimized structures on tables
Mach5 builds and maintains lightweight, search-oriented index structures side-by-side with your Iceberg tables. These are not copies of the full dataset in a proprietary store; they are auxiliary structures that accelerate common search operations (e.g., n-gram/token maps for phrases and prefixes, positional hints for ordered terms).
•
Native search capability
Analysts query using intuitive search syntax (compatible with Elastic/OpenSearch-style patterns), and Mach5 executes with low-latency semantics: typo tolerance, phrase matching, field boosting, and ranking that surfaces the right records first.
•
Search UX for security/observability
Mach5 exposes faceting, filtering, saved searches, dashboards, and alerting, the tools analysts expect when they’re in the middle of an investigation.
The Mach5 + Cloudflare approach provides a fresh and efficient edge to the use case. Cloudflare’s platform remains the immutable source of truth, responsible for reliable ingestion and storage. Mach5 provides a disposable, high-performance indexing and query layer that can be scaled independently. The Iceberg table format is the contract that ensures both systems can work together seamlessly
Why Mach5 Search on Iceberg/Cloudflare?
Adding Mach5 to your Cloudflare stack unlocks a whole new class of applications and workflows that are simply not feasible with SQL-based analytics alone. It closes the gap between data-at-rest and data-in-use.
•
True Sub-Second, Needle-in-a-Haystack Queries
For a SOC analyst, this means being able to search for an indicator of compromise across a year's worth of logs and get results instantly. For an SRE, it means filtering a dashboard to a single customer ID that is experiencing issues and seeing all their logs, metrics, and traces populate immediately.
•
Rich, Interactive Search Experiences
Modern UIs require more than just a list of results. Mach5 provides native support for faceted navigation, allowing users to slice and dice search results on the fly. After searching for “404 Not Found,” a user can instantly see a breakdown of the top URLs, client IP addresses, and user agents, allowing for rapid root cause analysis. It also supports relevance ranking and typo tolerance, which is crucial for creating a user-friendly search experience.
•
Purpose-Built Dashboards & Alerts for Operations
Mach5 isn't just a query engine; it's an application platform. You can build real-time dashboards that are optimized for security and observability workflows visualizing login failures by geographic location, charting API endpoint latency, or creating live-tailing views of logs for a specific service during a deployment. Alerts can be configured on top of any query, notifying your teams in Slack or PagerDuty the moment an anomaly is detected.
•
Critical Workload Isolation
Mach5’s decoupled architecture completely isolates search workloads from both the data ingestion pipeline and any large-scale analytical queries running against Iceberg. Your SOC team’s urgent threat hunt will never be slowed down by the data science team’s quarterly report generation, and vice-versa.
•
A Guaranteed Single Source of Truth
By avoiding data duplication, you eliminate the risk of data drift, stale copies, and synchronization errors. Your search results are always consistent with the underlying data in your Iceberg tables, ensuring everyone in the organization is working from the same trusted dataset.
Quickstart Guide
This is the minimum viable path from “raw events” to “a first useful search dashboard”:
1. Configure Cloudflare Pipelines to Iceberg
- Define one or more event inputs (HTTP endpoints, Workers bindings, etc.).
- Normalize incoming payloads (flatten nested JSON where it aids search, standardize timestamps and tenant identifiers).
- Redact sensitive fields at the edge if needed.
- Land records into R2 as Iceberg tables with a sensible partitioning scheme like hourly or daily time buckets are a good baseline, plus a high-selectivity dimension like tenant_id or env.
2. Enable and monitor compaction
- Compaction counteracts the natural small-file accumulation from streaming writes.
- Set a cadence that aligns with ingest volume and your target search latencies.
- Keep an eye on “files per partition,” average file size, and the variability of query times as your early performance signals.
3. Connect Mach5 to your Iceberg catalog
- Register the table locations and schemas.
- Identify which fields are searchable text (error messages, user agents, URLs) vs filterable dimensions (tenant, env, region, service).
- Decide which facets you’ll surface by default (e.g., source_ip, service, status_code, country).
4. Configure indexing strategies in Mach5
- Enable index structures that map to your workloads:
- n-grams or positional tokens for phrase and prefix matches.
- Variant maps for typo-tolerant matching on critical fields (e.g., hostnames, user names).
- Sub-pointer 1 under variant maps
- Sub-pointer 2 under variant maps
- Start with a small set of hot fields and expand once you validate gains.
5. Publish dashboards, saved searches, and alerts
- Ship an initial Security Analytics dashboard with:
- KPIs: total events, error rate, auth failure rate, unique IPs.
- Top-N panels: top services, top error codes, top source IPs, top user agents.
- Trend charts: auth failures by minute/hour, anomalies per region.
- Create “pivotable” saved searches like:
- Auth Failures (Last 24h): facet by source_ip, filter by tenant_id.
- Suspicious User Agents: phrase search on UA substrings.
- Bursting 5xx Errors: combine a trend spike detector with a phrase filter on the error message.
- Add alerts for meaningful thresholds (e.g., “Auth failures 2× baseline for tenant X in 15 minutes”).
This path puts a working search experience in front of analysts quickly, without re-architecting the lake or standing up extra infrastructure.
The Expected Outcome: Performance, Cost and Simplicity
Adopting this modern, composable architecture delivers compounding benefits across three key areas:
•
Performance
The outcome is a dramatic acceleration of insight. Queries that previously took minutes of scanning now return in milliseconds. This isn't just a quality-of-life improvement; it's a strategic advantage that directly reduces Mean Time to Resolution (MTTR) for incidents and accelerates threat detection and response cycles.
•
Cost
The TCO reduction is substantial. First, you eliminate storage duplication, effectively cutting your storage bill for search data to zero. Second, you benefit from R2's zero egress fees, meaning you aren't penalized for using a best-of-breed search tool. Third, Mach5’s serverless-like architecture means you avoid paying for a large, idle search cluster. Finally, you save on the significant operational overhead required to manage, scale, and secure a separate distributed system.
•
Simplicity
This architecture is elegantly simple. You are not stitching together a brittle, complex Rube Goldberg machine of ETL jobs, data copies, and synchronization scripts. You are composing two powerful, managed services on top of a resilient, open standard. This reduces architectural complexity, minimizes points of failure, and frees up your engineering team to focus on delivering value instead of managing infrastructure.
•
Future-Ready
This stack positions you perfectly for the future. As AI and LLMs become more integrated into analytics, having your data in a single, open, and indexed repository is a massive advantage. Adding vector embeddings to your data for semantic search or building conversational analytics bots becomes a natural extension of your existing architecture, not a complete overhaul.
Conclusion
The era of choosing between a powerful, cost-effective data lake and a fast, feature-rich search engine is over. The combination of the Cloudflare Data Platform and Mach5 Search proves you can have both. Cloudflare provides the world-class, open data backbone to reliably store your data for the long term. Mach5 provides the high-performance search engine you need to activate that data for immediate, mission-critical action all without ever moving or duplicating it. You get the scale and economics of a data lake with the speed and interactivity of a dedicated search cluster.
Stop wrestling with complex data pipelines and slow queries. Schedule a Demo to connect your R2/Iceberg dataset to Mach5 and experience sub-second search, facets, and dashboards