10 Billion Rows, 1/15th the Infrastructure: How Mach5 Outperforms Trino, Starburst, and Snowflake
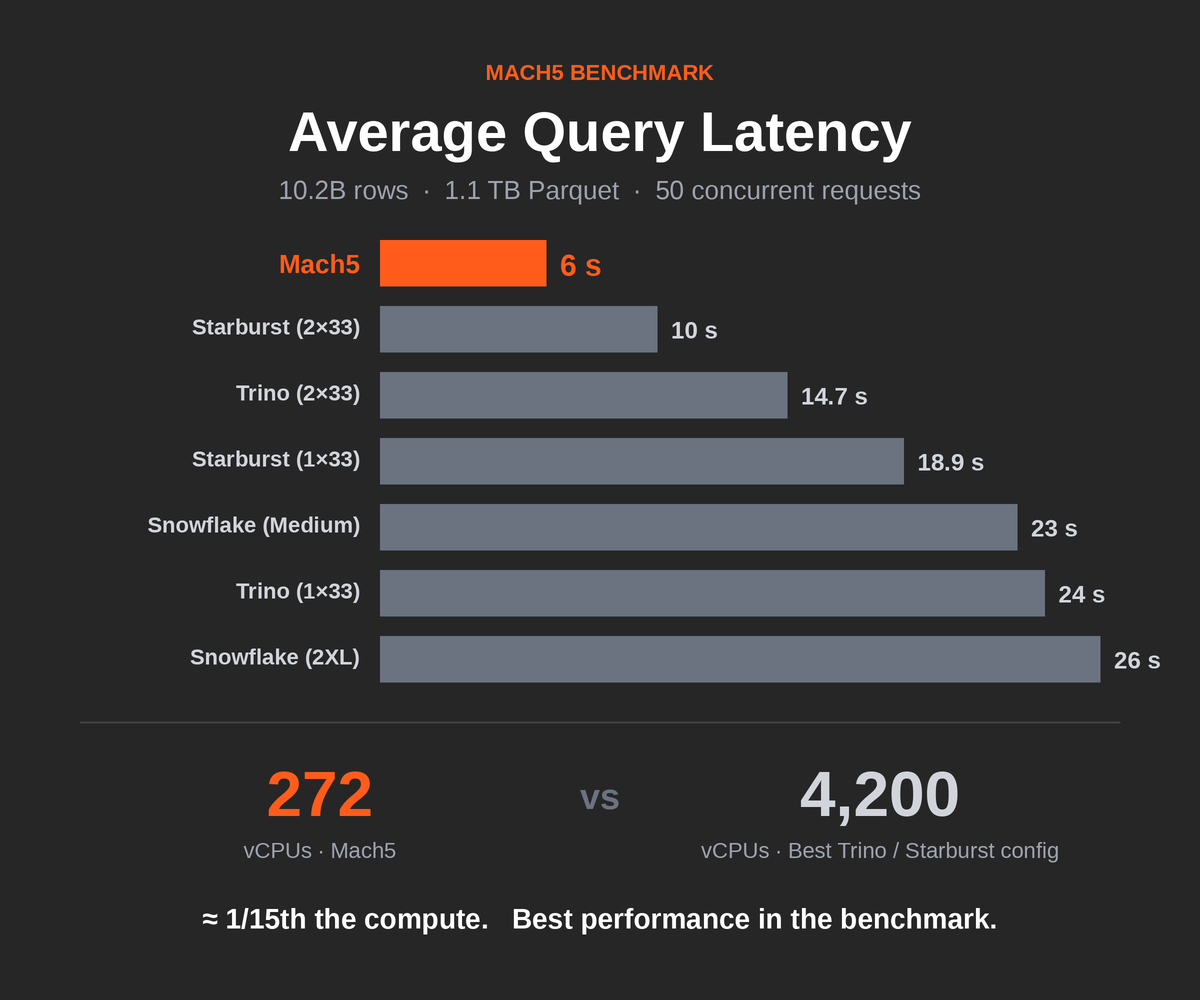
TABLE OF CONTENTS
Need Help?
Our team of experts is ready to assist you with your integration.
When a Fortune 500 company needed to evaluate search and analytics platforms for their high-volume telemetry workload, they didn’t take anyone’s word for it. They ran a rigorous, head-to-head benchmark across four platforms (Trino, Starburst, Snowflake, and Mach5) on real production data at real scale.
The results weren’t close.
The Benchmark
The test was straightforward: perform search over a logs table from their largest tenant spanning 15 days of data: 1.1 TB of Parquet files containing 10.2 billion rows, with an average ingest rate of roughly 680 million rows per day. All platforms were tested at 50 concurrent requests to simulate realistic production load.
Each platform was given its best-foot-forward configuration. Trino and Starburst were each tested in two configurations, scaling up to 2 clusters of 33 nodes (1 coordinator + 32 workers) using m7gd.16xlarge instances, some of the beefiest compute available on AWS. Snowflake was tested with both a 2XLarge and a Medium warehouse, each running 7 clusters. Mach5 ran on 6 modest m6id.2xLarge instances for indexing and compaction, and 7 c6id.8XLarge instances for querying.
The Results
| Platform | Configuration | Avg Latency | P95 Latency |
|---|---|---|---|
| Mach5 | 6 + 7 nodes (see below) | 6 s | 18 s |
| Starburst | 2 × 33 nodes, m7gd.16xlarge | 10 s | 21 s |
| Trino | 2 × 33 nodes, m7gd.16xlarge | 14.7 s | 24 s |
| Starburst | 1 × 33 nodes, m7gd.16xlarge | 18.9 s | 38 s |
| Snowflake | GEN2 Medium WH, 7 clusters* | 23 s | 59 s |
| Trino | 1 × 33 nodes, m7gd.16xlarge | 24 s | 50 s |
| Snowflake | GEN2 2XLarge WH, 7 clusters | 26 s | 42 s |
*Snowflake Medium WH was tested at only 15 concurrent requests versus 50 for all other configurations.
Mach5 delivered the fastest average query performance at 6 seconds, 1.7× faster than the best Starburst configuration, 2.4× faster than the best Trino configuration, and over 4× faster than Snowflake.
At P95, which is what matters when you’re investigating a security incident at 2 AM and every second counts, Mach5 came in at 18 seconds, versus 21 seconds for the best competitor and 59 seconds for the worst.
The Infrastructure Gap Is the Real Story
Raw performance is impressive, but the infrastructure required to achieve it is where the picture gets dramatic.
Trino and Starburst’s best configurations used 2 clusters of 33 m7gd.16xlarge instances. Each of those instances packs 64 vCPUs. That’s roughly 4,200 vCPUs working in concert.
Mach5 used 6 m6id.2xLarge instances (8 vCPUs each) for indexing and compaction, plus 7 c6id.8XLarge instances (32 vCPUs each) for querying. Total: 272 vCPUs.
That’s approximately 1/15th the compute, and it delivered the best performance in the benchmark.
Snowflake’s managed infrastructure makes a direct vCPU comparison harder, but a 2XLarge warehouse with 7 multi-clusters is a substantial (and expensive) deployment by any measure, and it still came in last on average latency.
Why the Gap Exists
This isn’t a story about clever tuning or finding the right instance types. The performance gap is architectural.
Trino, Starburst, and Snowflake are general-purpose query engines designed to scan columnar data formats like Parquet. They’re powerful tools for analytical workloads like BI dashboards, reporting, and data transformation. But when the workload is search (finding specific events, filtering by time ranges, matching patterns across billions of rows) they have to brute-force their way through the data. More data means more nodes, linearly.
Mach5 is a purpose-built search and analytics engine. Instead of scanning Parquet files at query time, Mach5 indexes data at ingest, building structures optimized for the kinds of queries that security, observability, and product analytics teams actually run. The result is that queries touch a fraction of the data, which means a fraction of the compute, which means a fraction of the cost.
It’s the difference between searching a library by reading every book versus using the card catalog.
What This Means for Teams Running High-Volume Telemetry
If you’re running a security analytics, observability, or product analytics workload at scale, you’ve likely felt the tension: data volumes keep growing, query performance keeps degrading, and the infrastructure bill keeps climbing. The standard playbook (throw more nodes at the problem) works until it doesn’t.
This benchmark shows there’s a different path. Purpose-built architecture can deliver better performance on dramatically less infrastructure. That’s not just a cost savings. It’s operational simplicity. Fewer nodes means fewer failure modes, less configuration surface area, and faster time to production.
The Fortune 500 company that ran this evaluation chose Mach5. They chose it because the numbers made the decision obvious.
To learn more about the Mach5 Search Platform and run your own benchmark, visit mach5.io.


