#Using Databricks with Mach5 Search
Mach5 Search is a cloud-native search and indexing engine optimized for large-scale machine data and log analytics. When integrated with Databricks and Delta Lake, it allows users to run full-text search and aggregations over structured and semi-structured data stored in Delta format, without duplicating the underlying dataset.
Key advantages include:
- Native support for object storage and multiple data lakes
- Separation of indexing and serving workloads
- ElasticSearch-compatible query APIs
- 90% lower TCO compared to traditional ELK stacks
Prerequisites
To integrate Mach5 Search with Databricks, ensure the following:
- A Databricks workspace with Delta Lake tables available
- Access to a supported cloud object store (e.g., AWS S3, Azure Blob, GCS)
- Permissions to run Databricks jobs or notebooks
- A deployed Mach5 Search instance (hosted or self-managed
- Kibana or notebook interface for querying (optional)
Component Overview
- Delta Lake(Databricks) :Primary storage for structured event/log data.
- Mach5 Indexer :Runs in Databricks to convert Delta tables into search indexes.
- Object Storage :Stores the inverted indexes produced by the indexer.
- Mach5 Search :Stateless search layer that loads and serves indexes.
- Query Interface :Kibana dashboards, notebooks, API clients.
Deployment Architecture
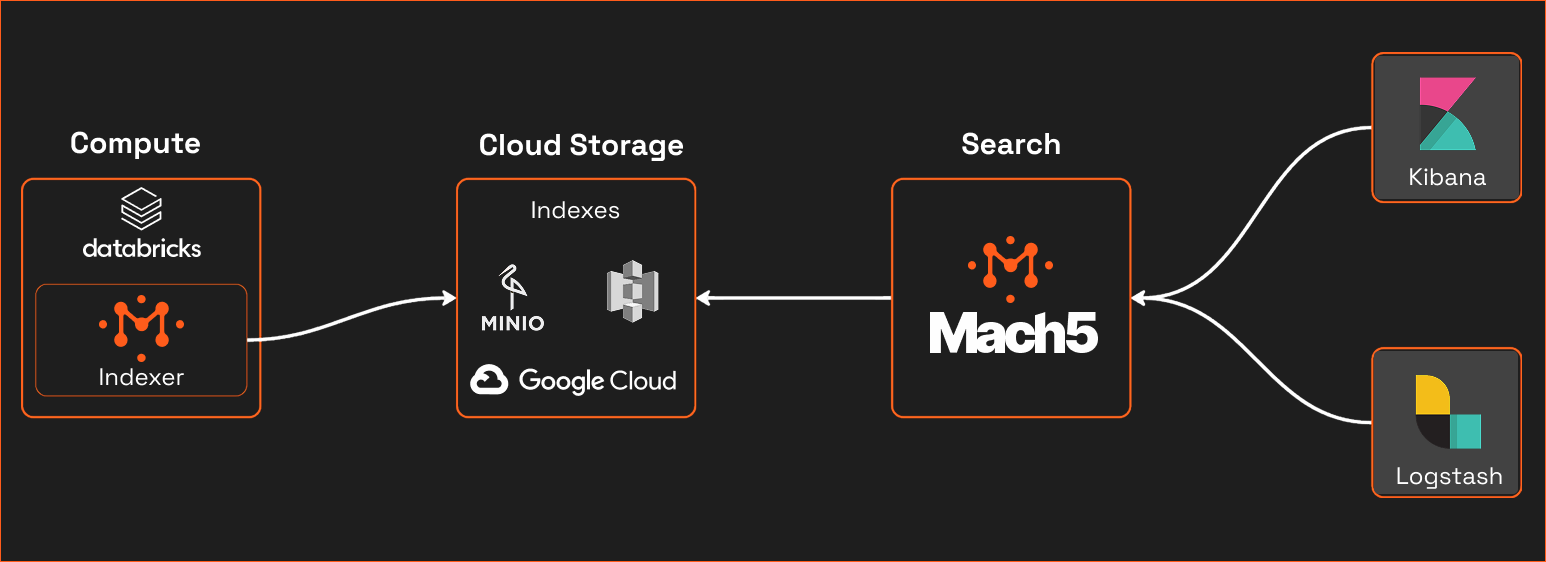
- indexing is decoupled from search querying.
- Indexes are durable and scalable via object storage
- Stateless architecture allows elastic scaling of search nodes
Data Flow
- Raw data is ingested into Delta Lake tables in Databricks
- Mach5 Indexer runs as a job or notebook and reads from these tables
- Indexes are written to object storage in optimized format
- Mach5 Search loads indexes and serves queries
- Queries can be executed via Elastic DSL or API clients
Running Mach5 Indexer in Databricks
Execution Context
- Can be triggered manually, on a schedule, or via table updates
- Configurable via JSON/YAML or programmatically in notebooks
Example (Python Pseudo-code)
from Mach5 import indexer:
indexer = Indexer(
input_path="dbfs:/mnt/logs/delta",
output_path="s3://mach5-indexes/",
config={"fields": ["timestamp", "message", "host", "severity"]})
indexer.run()
- Supports field-level configuration and schema inference
- Fault-tolerant and restartable
Querying from Notebooks or Kibana
Mach5 exposes a REST API compatible with Elasticsearch, enabling:
- Real-time search from notebooks
- Visualizations via Kibana
- Integrations with SIEM and monitoring tools
Example (Python Pseudo-code)
POST /logs/_search
{
"query": {
"match": {
"message": "authentication failure"
}
},
"aggs": {
"by_host": {
"terms": { "field": "host" }
}
}
}
Ideal Mach5 usecases for Databricks
- Security analytics and alert investigations on Delta Lake logs
- Real-time observability and dashboarding over machine data
- SIEM augmentation without duplicating data into Elasticsearch
- Unified data pipelines using Spark + Mach5 for search at scale
- Cost-efficient operational search over petabyte-scale log volumes
Need help?
If you have any questions about setting up Mach5 Search and need live help, please email us at: info@mach5.io
Just getting started or exploring on your own? Join the conversation in the Mach5 Discord Community - a space to ask questions, share ideas, and learn from other engineers building with Mach5.